MySQL NDB Cluster: High Availability
With its distributed, shared-nothing architecture, MySQL NDB Cluster has been carefully designed to deliver 99.999% availability ensuring resilience to failures and the ability to perform scheduled maintenance without downtime.
Protecting against outages:
- Synchronous Replication - Data within each data node is synchronously replicated to another data node.
- Automatic Failover - MySQL NDB Cluster's heartbeating mechanism instantly detects any failures and automatically fails over, typically within one second, to other nodes in the cluster, without interrupting service to clients.
- Self Healing - Failed nodes are able to self-heal by automatically restarting and resynchronizing with other nodes before re-joining the cluster, with complete application transparency
- Shared Nothing Architecture, No Single Point of Failure - each node has its own disk and memory, so the risk of a failure caused by shared components such as storage, is eliminated.
- Geographical Replication - Geographic replication enables nodes to be mirrored to remote data centers for disaster recovery.
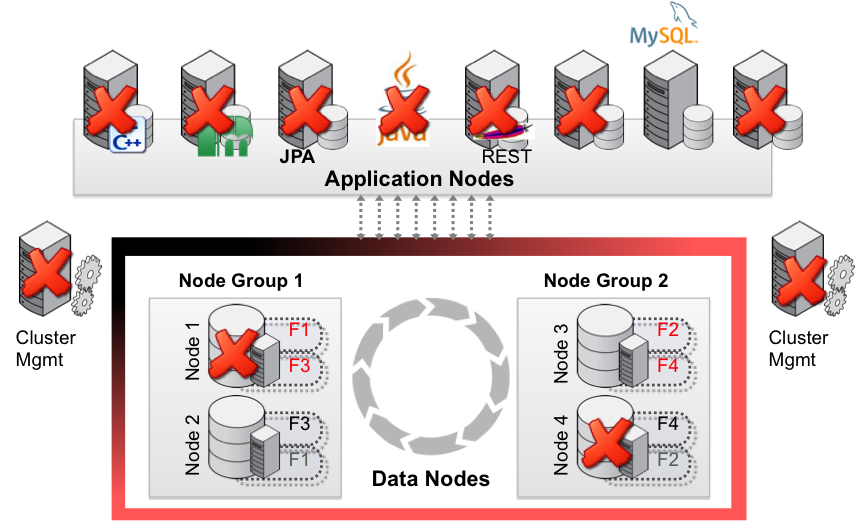
Figure 1: With no single point of failure, MySQL NDB Cluster delivers extreme resilience to failures.
MySQL NDB Cluster also protects against the estimated 30% of downtime resulting from scheduled maintenance activities by allowing on-line operations, including:
- On-Line schema updates
- On-Line scaling (adding nodes for capacity and performance)
- On-Line upgrades and patching of hosts, OS and database
- On-Line backup